
I Ran the Same Coding Task Across 8 AI Models — Then I Did It Again

I Ran the Same Coding Task Across 8 AI Models — Then I Did It Again
A free model reached the top tier. Then it didn’t hit it again.
All Redis code excerpts and timing data published for independent verification: github.com/shaileshjgd/FrontierModelEvals
I build large-scale ML and analytics systems, and I’ve spent the better part of the past year trying to answer one question honestly: which AI models actually hold up when the output needs to go to production, not just pass a demo? My previous piece argued that fluency without justification is insufficient for production AI systems. This is the empirical follow-up — applied to the tools engineers use every day.
On April 2, 2026 — the same day Google released Gemma 4 — I ran a controlled benchmark across eight of the most capable AI models available. The task: write a production-ready sliding window rate limiter for Express.js, complete with Redis adapter, TypeScript types, and real unit tests. The kind of thing a senior engineer might spend half a day on.
Then I ran it again. And again. Because a single run isn’t a finding — it’s a data point.
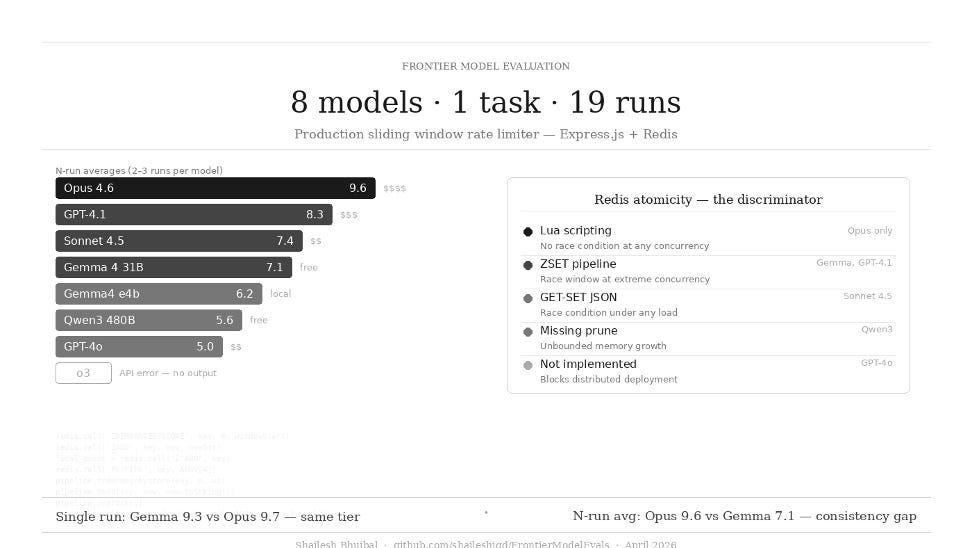
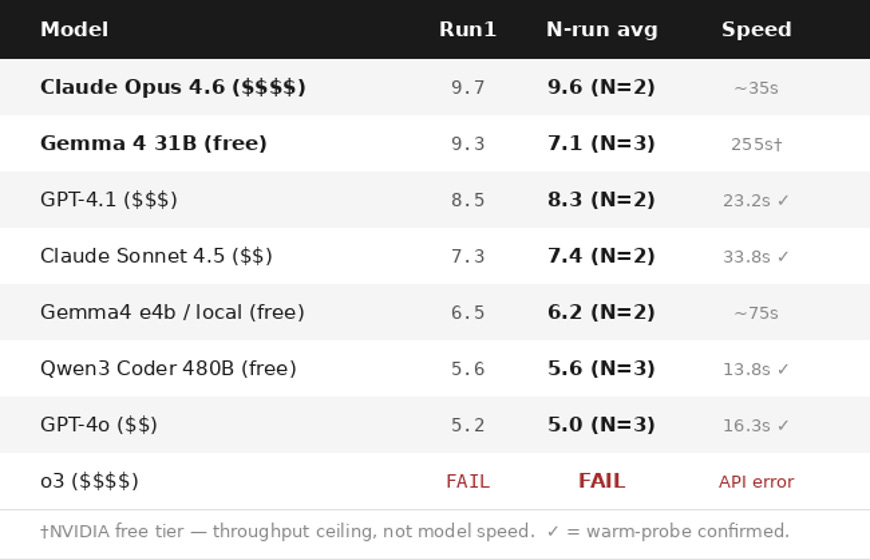
The single-run result: Google’s Gemma 4 31B, accessible for free via NVIDIA’s inference gateway, scored 9.3/10 vs. Claude Opus 4.6’s 9.7 — both in the top tier. That’s the headline many people would stop at.
The multi-run result is more interesting: Opus was consistent across both runs (9.7, 9.5 — avg 9.6). Gemma was high-variance (9.3, 6.3, 5.7 — avg 7.1). The top-tier ceiling is real. Hitting it consistently is not.
I want to be precise about what that means and what it doesn’t, because the details matter.
Why This Task, Not HumanEval
Before getting into results, I need to address the benchmark selection. HumanEval, MBPP, and SWEBench are all useful, but they don’t capture what separates a capable junior engineer from a strong senior one on real infrastructure tasks. This benchmark task was designed to require simultaneously:
Algorithmic correctness — sliding window log, not the simpler fixed-window approximation
Distributed systems reasoning — Redis atomicity, race condition avoidance
Production operations thinking — fail-open error handling, memory leak prevention, connection lifecycle
Test engineering — fake timers for deterministic sliding window validation, not just happy-path assertions
API design discipline — RFC-compliant headers, pluggable storage abstraction
This is the kind of task where the difference between a technically correct and a production-safe implementation is invisible to a quick read-through — and where AI-generated code poses real operational risk if used without expert review.
The Models, Honestly Described
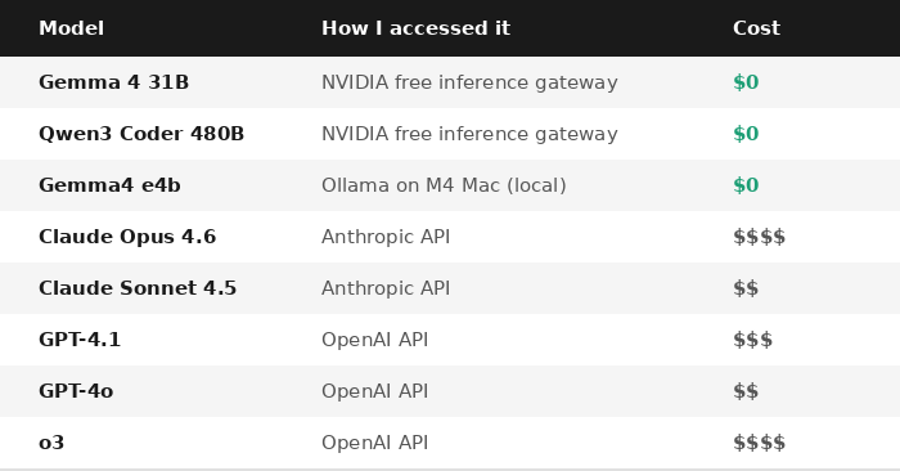
One immediate finding before a line of code was evaluated: o3 produced no output. OpenAI migrated o3 to require max_completion_tokens instead of max_tokens — a documented parameter change that the evaluation script hadn’t yet adopted. The API returned a 400 error in 1.1 seconds. It’s a migration, not instability — but it illustrates why AI API changelogs belong in your dependency monitoring process alongside npm and pip.
A note on model versions: Claude Sonnet 4.6 was released in February 2026 but was not included in this run. The benchmark used the model versions in active production use in my tooling as of April 2. Sonnet 4.5 was the Sonnet-tier model in that configuration. Sonnet 4.6 will be included in the next eval.
The Scoring Rubric
I scored each response on six dimensions (1–10 each), averaged for a final score:
1. Strategy & Architecture — Is there a clear layered design with explicit reasoning?
2. Code Correctness — Is the sliding window semantics right? Any bugs?
3. Redis Implementation — What’s the atomicity level?
4. Test Quality — Do tests actually validate the sliding window property?
5. Production Readiness — Fail-open? Memory safe? Headers RFC-compliant?
6. Drop-in Readiness — Can you use this with minimal editing?
The Results
The Finding That Surprised Me Most: Redis is the Discriminator
When I set out to evaluate these models, I expected the differentiation to appear in code correctness or architectural clarity. Instead, the single dimension with the widest variance — and the most direct production risk implication — was Redis implementation quality.
Here’s the stratification:
Lua scripting — Only Claude Opus 4.6
Opus implemented Redis rate limiting via Lua scripts: ZREMRANGEBYSCORE + ZADD + ZCARD executed as a single atomic transaction. This is the only approach that is provably correct under arbitrary concurrency. No race condition is possible because the script runs atomically on the Redis server.
ZSET Pipeline — Gemma 4 31B and GPT-4.1
Both used Redis sorted sets with pipelined commands. The pipeline batches network round-trips but is not atomic — there’s a theoretical race window between the count check and the write. At typical API gateway throughput, this is acceptable. Both scored 8–9 on this dimension.
SETEX with JSON blob — Claude Sonnet 4.5
This is the one that should concern practitioners. Sonnet stored timestamp arrays as JSON strings, using SETEX for TTL. The sequence is: GET → deserialize → filter → push → SET. Two concurrent requests can both read the same count, both decide “allowed,” and both write back — causing the rate limit to be exceeded under concurrent load. This isn’t a theoretical edge case; it’s the expected behavior at any meaningful traffic volume.
Not implemented / Fixed window — GPT-4o
GPT-4o run1 described a Redis approach in prose but provided no code. Run3 implemented code — but the wrong algorithm: an INCR+PEXPIRE fixed-window counter, not a sliding window log. Both are unusable for distributed deployment as specified.
Missing prune call — Qwen3 Coder 480B
Qwen3’s Redis code counted entries with ZRANGEBYSCORE but never called ZREMRANGEBYSCORE to remove expired ones. The ZSET grows without bound under sustained traffic. The per-window count stays correct (the range query filters properly), but the key accumulates all historical entries — a memory leak that only surfaces in distributed deployment.
What Made Gemma 4 31B Score 9.3 on Run1 — And Why It Dropped
Let me be specific, because vague model praise is noise. Here’s what Gemma 4 produced in run1 that justified a 10 in multiple categories:
Architecture: It opened with an explicit component table mapping each layer (StorageAdapter, RateLimiter, RateLimitMiddleware, Config) to its responsibility and stated its complexity analysis unprompted: O(N) for memory store operations, O(log N) for Redis sorted set operations.
Code Correctness: The sliding window logic was exact — count < limit (not <=, which is a common off-by-one), timestamp prune-before-count ordering, correct branching without penalizing the user by counting the rejected request.
Tests: Three real Jest tests, including jest.useFakeTimers() for the sliding window expiry test. This is the test that actually validates the algorithm, not just happy-path behavior.
Production thinking: Fail-open try-catch with structured error handling, pexpire for automatic Redis key cleanup on idle users, and Retry-After header calculation using the oldest timestamp in the window — the correct value, not a fixed offset.
What Claude Opus 4.6 did better: Lua scripting for full atomicity, binary search for O(log N) timestamp pruning, picomatch glob routing, sweepInterval.unref() for Node.js process safety, and a shutdown() lifecycle hook.
Why runs 2 and 3 dropped: One specific detail separated them from run1. Run1’s Redis implementation added entries speculatively, then did a follow-up ZREM to clean up entries for rejected requests — so a blocked user’s timestamps didn’t contaminate their next window. Runs 2 and 3 omitted the cleanup. It’s 3 lines of code. The model knows the concept — it demonstrated it on run1 — but didn’t produce it consistently. That’s the variance story in a single bug: 9.3, 6.3, 5.7, average 7.1.
The Speed Surprise
I ran two timing probes across the NVIDIA free tier models, and the results revealed something important about how free-tier inference works.
Probe 1 (earlier in the day):
Qwen3 Coder 480B: 1,213ms for 100 tokens
Gemma 4 31B: 54,984ms for 100 tokens
Probe 2 (an hour later):
Gemma 4 31B: 2,661ms for 80 tokens ← warm model
Qwen3 Coder 480B: 4,675ms for 80 tokens ← queue depth increased
Nemotron 49B: 1,855ms for 80 tokens
The 55-second Gemma 4 31B result wasn’t the model being slow — it was a cold-start artifact. When the model is warm and queue depth is low, Gemma 4 31B responds in under 3 seconds, comparable to everything else. NVIDIA free-tier latency is primarily a function of queue state, not model architecture. It’s variable in ways that matter for interactive use but are invisible in isolated benchmarks.
What this means in practice:
Architectural design sessions: Gemma 4 31B — occasionally slower, always higher quality
Confidential code: Claude Sonnet 4.5 via Anthropic API (enterprise data controls, consistent latency)
Absolute highest stakes / production infrastructure: Claude Opus 4.6 — Lua atomicity was consistent across both runs (9.7, 9.5)
What This Means
On this class of task — distributed systems middleware with a concurrency-sensitive correctness requirement — the best free model landed in the same tier as the best paid model on a single run: 9.3 vs. 9.7, a 0.4-point gap. That result doesn’t generalize to all engineering tasks, but it’s a strong signal that the assumption “you need the most expensive model for serious work” deserves scrutiny, not blind acceptance. The tradeoffs worth evaluating are latency, data governance, and task fit — not a blanket capability gap that may no longer exist.
This has practical implications:
1. Teams routing all engineering tasks to Opus/o3 without evaluating task fit are likely over-spending for at least some of their use cases.
2. In this benchmark, Redis implementation quality was the highest-signal discriminator of distributed-systems reasoning depth — it requires simultaneous understanding of concurrency, atomicity, and operational constraints, dimensions that standard coding benchmarks do not measure.
3. NVIDIA’s free inference gateway is a serious tool for professional engineering, not just experimentation. The combination of Gemma 4 31B (architecture) and Qwen3 480B (implementation) covers most of the engineering workflow at zero cost.
4. API changelog monitoring belongs in your dependency stack. o3’s parameter migration broke evaluation before a single token was generated. Track AI API breaking changes the same way you track npm and pip — it’s a production dependency with the same operational requirements.
Caveats I Want to Be Explicit About
Multi-run data. I ran additional independent calls for six of eight models (2–3 runs each). The N-run averages in the results table above reflect this. Broad structural patterns (Lua vs. GET-SET, Redis vs. not, fake timers) were consistent. Implementation quality within a pattern was not — Gemma 4 31B’s ZREM cleanup appeared in run1 and not runs 2 or 3. Models within 1.0 point of each other should be treated as approximately equivalent given single-scorer variability and LLM stochasticity.
One task, one domain. These conclusions apply to distributed systems and middleware tasks. Generalizing to all software engineering would be overreach.
Conflict of interest disclosed. I use NVIDIA’s free tier in my own tooling. I have a stake in free-tier models performing well. Scores were assigned before models were compared against each other.
Anthropic timings are warm-timed. A short warm probe fired first; the full task fired immediately on return. Sonnet 4.5 confirmed at 33.8s; Opus 4.6 estimated at ~35s from prior run.
All Redis code excerpts, scoring rationale, and timing data are published publicly for independent verification: github.com/shaileshjgd/FrontierModelEvals
On a single run, a free model reached the same tier as the best paid model (9.3 vs. 9.7). Across multiple runs, Opus held its ceiling consistently while Gemma showed real variance. Both findings matter. The ceiling result tells you what’s possible on the free tier. The variance result tells you not to ship code from a single free-tier generation into a distributed system without review. The consistency result tells you what you’re actually buying when you pay for Opus.
For this benchmark task class — and likely adjacent middleware and concurrency-sensitive tasks — the free tier gets you 70–90% of the ceiling in practice. The remaining gap shows up in exactly the operational details you’d miss in a code review but feel in a production incident.
Full methodology and raw outputs
Full methodology report (6-dimension rubric, per-model Redis analysis, timing methodology, limitations, all 19 raw outputs):
github.com/shaileshjgd/FrontierModelEvals → REPORT.md
Raw outputs, scoring rationale, and Redis code excerpts from every model:
github.com/shaileshjgd/FrontierModelEvals → 2026-04-02 evals folder
Tags: #AIEngineering #LLM #MachineLearning #SoftwareEngineering #Gemma4 #CloudAI #OpenSource #RateLimiting #Redis #TypeScript